
Die Datenquellen-Option "Aus Ordner" ist ein sehr nützliches Feature, das Nutzern in Excel und Data-Analysten in Power BI viel Zeit und Aufwand beim Import und der Kombination vieler Datei-Datenquellen ersparen kann.
Besonders komfortabel ist die Funktionalität, wenn die zu verarbeitenden Daten in Dateien mit identischer Zeilen- und Spaltenstruktur vorliegen. In der täglichen Praxis kommt es aber häufig vor, dass gerade das nicht der Fall ist. Wie kannst Du also vorgehen, wenn Du einen Ordner-Import für unterschiedlich strukturierte Dateien realisieren willst? Lese dazu meinen Praxistipp...
Was ist eigentlich die Problemstellung?
Das klassische Vorgehen für den Import diverser Dateien aus einem Ordner wurde an anderer Stelle schon häufig vorgestellt. Auf dem Blog von SQLXPERT findest Du zum Beispiel diesen Beitrag von Imke Feldmann, in dem sie das grundlegende Vorgehen beim Import von identisch strukturierten Excel-Dateien vorstellt.
Kostenrechnungs- oder Buchhaltungssysteme können in der Praxis aber Datenexporte mit unterschiedlichen Strukturen, also Anzahl an Spalten und Zeilen bzw. unterschiedliche Überschriften, ausgeben.
Ein Beispiel für ein solches System ist das Kostenrechnungsmodul von Datev. Typische Reports, die man aus Datev exportieren kann, sind die so genannten "Chefreports". Diese können z.B. als Zeilenüberschriften die verschiedenen Erlös- bzw. Kostenpositionen und als Spaltenüberschriften die verschiedenen Kostenstellen einer Gesellschaft zeigen. Wenn Du nun aber mehrere Gesellschafts-Mandanten in Datev hast, kannst Du diesen Report für jede Gesellschaft exportieren. Da die unterschiedlichen Gesellschaften mitunter andere und unterschiedlich viele Kostenstellen haben und nicht bei jeder Gesellschaft jede Erlös- bzw. Kostenposition Beträge enthalten muss, können die Exporte in der Struktur ihrer Zeilen und Spalten voneinander abweichen. Die folgende Abbildung zeigt drei mögliche Beispielexporte:
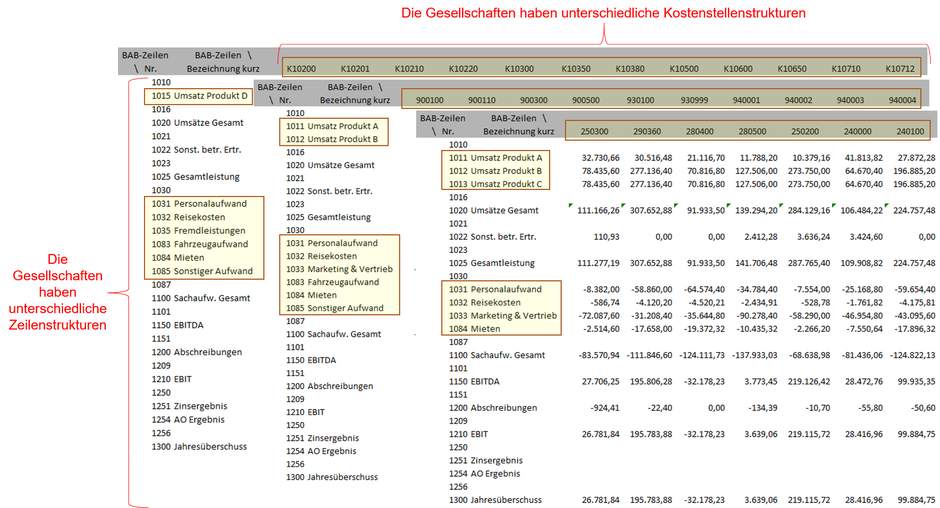
Wenn Du diese Dateien nun aus einem Ordner via Power Query nach Excel oder Power BI importieren und miteinander kombinieren möchtest, dann erhältst Du folgende Datenstruktur:
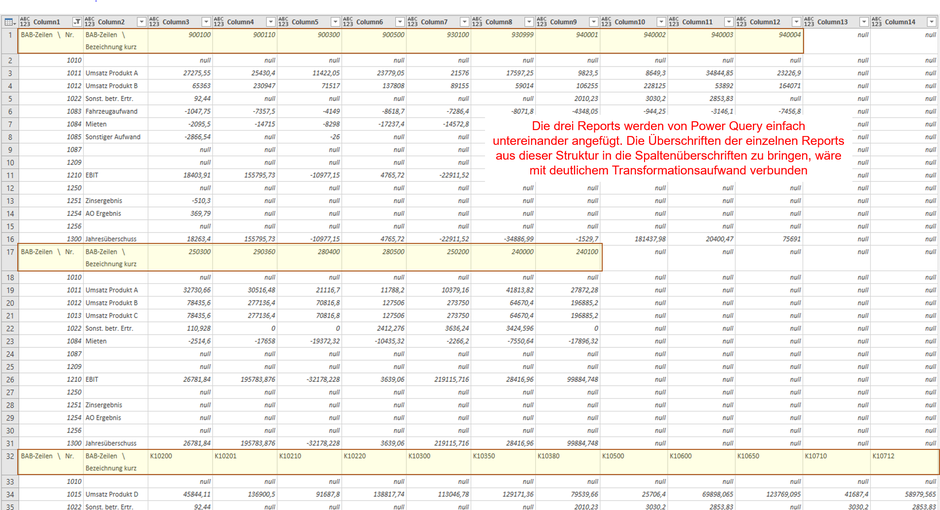
Dein Ziel sollte es sein, diese Kreuztabellen-Struktur in eine Tabellenstruktur mit den Kostenstellen und Beträgen als Datensätze in den Tabellenzeilen zu überführen, damit Du die kombinierten Daten der Gesellschaften sinnvoll im Datenmodell oder auch in einer Excel-Tabelle für weitere Auswertungen nutzen kannst. Die folgende Abbildung zeigt das angestrebte Ergebnis:
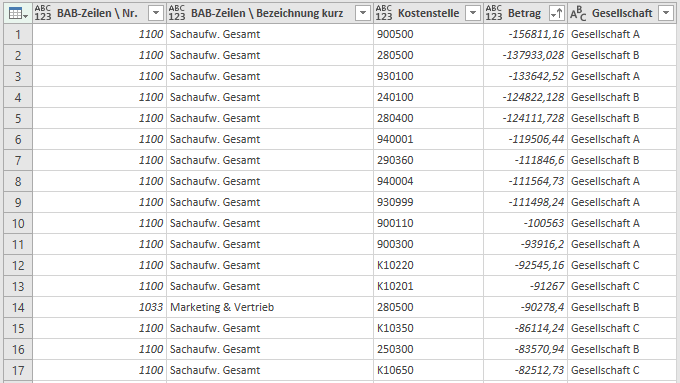
Um diese Struktur aus den variablen Datenquellen zu erzeugen, also vor allem die verschiedenen Kostenstellen in eine Spalte zu transformieren, wären eine Reihe, teils komplizierter, Transformationsschritte notwendig.
Mein Lösungsvorschlag für die Problemstellung!
Durch eine leicht veränderte Herangehensweise an das Problem und ein paar M-Funktionen kannst Du eine Import-Prozedur erzeugen, die Dir zuverlässig, weil unabhängig von der Variabilität in den Datenstrukturen, den Import und die Aufbereitung solcher Dateien aus Deinen Ordnern erlaubt. Du möchtest wissen wie? Dann schau Dir das folgende Video an:

Dieses Prinzip lässt sich natürlich nicht nur auf Excel-Dateien sondern auch auf andere Dateien (z.B. .txt oder .csv) anwenden, die Du gerne aus Deinen Ordnern importieren möchtest. Zudem funktioniert es natürlich neben Power Query für Excel auch im Power BI Desktop.
Die verwendeten M-Funktionen im Überblick
Folgende Funktionen werden in den einzelnen Schritten des Videos verwendet:
Schritt 1:
Table.PromoteHeaders(table as table, optional options as nullable record) as table
Funktionsweise:
Damit die unterschiedlichen Überschriften (Kostenstellen) der Beispieldaten in späteren Schritten durch Entpivotieren in Zeileneinträge umgewandelt werden können, werden sie zunächst zu Überschriften erhoben.
Die Funktion nimmt als ersten Parameter eine Tabelle auf und stuft die Werte der ersten Zeile dieser Tabelle zu Überschriften herauf. Die resultierende Tabelle mit den neuen Überschriften wird zurückgegeben. Der zweite, optionale Parameter ist für die Lösung nicht relevant und wird entsprechend nicht betrachtet.
Schritt 2:
Table.ColumnNames(table as table) as list
Funktionsweise:
Da die Spaltenanzahl und die Überschriften zwischen den einzelnen Gesellschaften variiert, kannst Du später beim Entpivotieren nicht mit einer festen Liste an Spaltennamen arbeiten. Vielmehr muss die Liste der zu entpivotierenden Spalten für jede Datei individuell ermittelt werden. Die Funktion liefert diese individuelle Auflistung der Überschriften je Gesellschafts-Datei.
Sie nimmt als einzigen Parameter eine Tabelle, in unserem Fall die resultierende Tabelle aus Schritt 1, auf und liefert eine Liste mit allen Spaltenüberschriften dieser Tabelle zurück.
Schritt 3:
List.FindText(list as list, text as text) as list
Funktionsweise:
Beim Entpivotieren soll vermieden werden, dass die ersten beiden Spalten des Berichts mit entpivotiert wird. In unserem Fall können diese Spalten durch den Textbestandteil "BAB" in den Überschriften über List.FindText identifiziert werden.
Die Funktion nimmt als ersten Parameter eine Liste, in unserem Fall die Liste der Spaltenüberschriften aus Schritt 2, auf. Der zweite Parameter ist der Textbestandteil, der in den Einträgen dieser Liste gesucht werden soll (in unserem Fall "BAB"). Die Funktion gibt eine Liste der Einträge zurück, die den Textbestandteil beinhalten.
Schritt 4:
Table.UnpivotOtherColumns(table as table, pivotColumns as list, attributeColumn as text, valueColumn as text) as table
Funktionsweise:
Die Funktion nimmt als ersten Parameter die Tabelle (das Resultat aus Schritt 1) auf, die entpivotiert werden soll. Als zweiter Parameter folgt dann die Liste der Spalten (aus Schritt 3), die nicht entpivotiert werden sollen. Im dritten und vierten Parameter kann der Überschriftentext festgelegt werden, den die Spalten tragen sollen, in die die Kostenstellen und Beträge entpivotiert werden. Im Beispiel sind dies die Überschriften "Kostenstelle" und "Betrag".

Durch die Entpivotierung der Kostenstellen und Beträge in die beiden neuen Spalten haben nun alle Quelldateien die gleiche Spaltenstruktur. Entsprechend einfach ist es nun in Power Query diese Daten im nachfolgenden Schritt zu kombinieren.
Durch das Vorschalten der gezeigten Transformationen vor die eigentliche Kombination der Daten ist es möglich, die Strukturen der Quelldateien zu vereinheitlichen und so einen Import- und Transformationsprozess zu erzeugen, der die Daten unabhängig von der Variabilität ihrer Zeilen- und Spaltenstrukturen automatisiert verarbeitet.
Was denkst Du darüber?
Du hast eine elegantere, einfachere, schnellere Lösung für diese Problemstellung? Dann her damit! Die anderen Leser und ich sind sehr an Deiner Lösung interessiert. Schreibe einfach einen Kommentar unter diesen Artikel. Auf jeden Fall wünsche ich Dir weiterhin viel Spaß bei der Nutzung der tollen Import-Option "Aus Ordner" in Power Query.
Dieser Praxistipp hat Dir gefallen? Du fandest ihn hilfreich? Dann teile ihn einfach mit anderen und schau bei meinem nächsten Beitrag wieder rein!
Viele Grüße aus Hamburg
Uwe



Kommentar schreiben
Thomas (Mittwoch, 15 Dezember 2021 12:15)
Hallo, gibt es ein Lösung für Dateien die ein unterschiedliches Schema haben und auch mehr Überschriften benötigen als in diesem Beispiel?
(War super erklärt und nachvollziehbar)
Thomas Huber